基于Python正则表达式提取搜索结果中的站点地址
2019/6/29 21:02:54

本文主要是介绍基于Python正则表达式提取搜索结果中的站点地址,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
正则表达式对于Python来说并不是独有的,最近在把google搜索的结果中所有的站点地址导出,于是想到用python正则表达式提取搜索结果中的站点地址。
这其中涉及几个需要解决的问题:
1、获取搜索的结果文本
为了获得更多的地址,我使用了Google的高级搜索功能,每个页面显示100条结果。
获得显示的结果后,可以查看源码,并保持成文本文件就有了搜索的结果文本
2、分析如何提取站点信息
首先需要分析获取的页面,查看以怎样的方式可以提取出站点信息。
我使用IE8自带的开发工具(按F12就会弹出来)中的探查器功能查看自己要关心的内容有什么特殊的格式
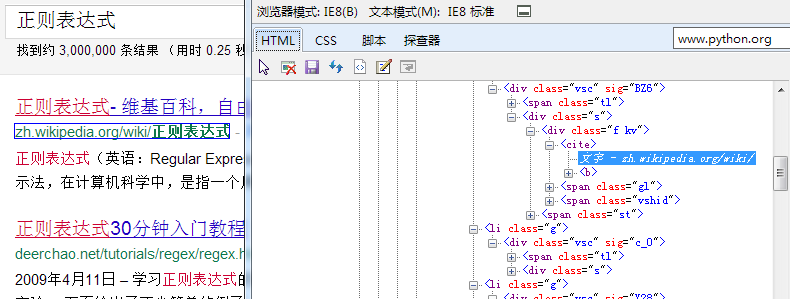
从上图可以看出我需要的站点在标签<cite></cite>中,所以我使用正则表达式提取这其中的文本是否就可以呢?
3、编写正则表达式来获取站点地址
接下来的就是写表达式了,我使用Python3.2编写的,方便好用(~_~)
代码如下,先把搜索结果页面保持到e:/t3.txt中,在执行如下代码
import re
p = re.compile(r'<cite>([^<>\/].+?)</cite>')
f = open("e:/t3.txt", encoding='utf-8')
content = f.read()
print ("\n".join(p.findall(content)))
运行如下:
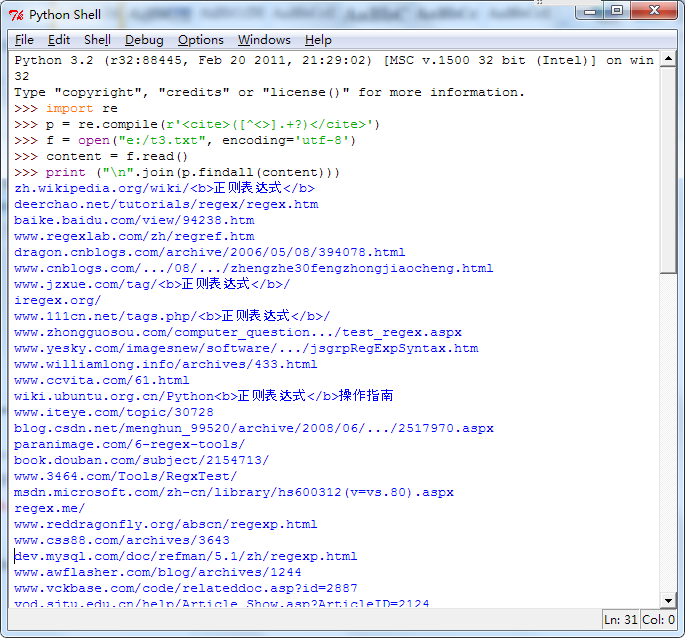
大家可以对照一下运行效果图,看看所有的站点地址是不是都给获取到了。
这篇关于基于Python正则表达式提取搜索结果中的站点地址的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-01-0939. 干货系列从零用Rust编写负载均衡及代理,正则及格式替换
- 2024-01-08如何编写高效的正则表达式?
- 2023-12-29"Matlab中的正则表达式:强大而灵活的工具"
- 2023-09-30这个正则 为啥同样的单号第二个就提取不出来?
- 2023-06-086.2 re 正则表达式
- 2023-06-06将字符串里的\x01,\x02这些替换掉用正则表达式无效?
- 2023-05-24正则表达式详解
- 2023-05-17我让gpt写了一段正则表达式代码,可是运行报错,可以帮忙看看哪里出了问题?
- 2023-04-27我要提取text4文本中的邮箱号 正则应该怎么写?
- 2023-04-15bash shell 无法使用 perl 正则



