深入Flink : 源码解读数据倾斜代码落地
2023/11/9 21:02:41

本文主要是介绍深入Flink : 源码解读数据倾斜代码落地,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
大家好,我是大圣,很高兴又和大家见面。
上篇文章,我们详细说了通过使得Flink 每个并行子任务上面都有对应的key 来 解决数据倾斜。
但是我们只说了这个方案的思想和设计理解,还没有把这种方案真正应用到我们的 Flink 任务当中。
这篇文章我们就重点把这种方案实践到我们写的 Flink 任务当中。
什么是数据倾斜
解决方案回顾
代码如下:
public class RebalanceKeyCreator {
private int defaultParallelism;
private int parallelism;
public RebalanceKeyCreator(int parallelism) {
this.parallelism = parallelism;
}
public Integer[] generateRebalanceKeys() {
int maxParallel = KeyGroupRangeAssignment.computeDefaultMaxParallelism(parallelism);
int maxKey = parallelism * 12;
Map<Integer, Integer> subIndexKeyMap = new HashMap<>();
for (int key = 0; key < maxKey; key++) {
int subtaskIdx = KeyGroupRangeAssignment.assignKeyToParallelOperator(key, maxParallel, parallelism);
if (!subIndexKeyMap.containsKey(subtaskIdx)) {
subIndexKeyMap.put(subtaskIdx, key);
}
}
return subIndexKeyMap.values().toArray(new Integer[0]);
}
}
这段代码的设计理念是确保每个并行度上面都分配一个唯一的key,确保均衡的key分配,从而实现均衡的数据分布。
代码实践
我会举一个不使用我们上面代码优化的 Flink 任务,让大家可以看到数据倾斜。
然后再把举一个经过我们上面方案优化过的 Flink 任务,让大家看到效果。
存在数据倾斜的例子
import com.atguigu.func.MyProcessFunction;
import com.atguigu.source.DataGeneratorSource2;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SkewedJob {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 8082);
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
// 定义数据源的最大用户ID和事件数量
int maxUserId = 100; // 假设我们有100个不同的用户ID
env.setParallelism(10);
// 使用自定义数据源
DataGeneratorSource2 dataSource = new DataGeneratorSource2(maxUserId);
// 将数据源添加到环境中,并定义后续的转换操作
SingleOutputStreamOperator<Tuple2<Integer, String>> skewedInput = env.addSource(dataSource)
.name("Custom Data Source")
.setParallelism(1);// 设置数据源的并行度
skewedInput
.map(new MapFunction<Tuple2<Integer, String>, Tuple2<Integer, String>>() {
@Override
public Tuple2<Integer, String> map(Tuple2<Integer, String> value) throws Exception {
return value;
}
})
.keyBy(event -> event.f0)
.process(new MyProcessFunction());
env.execute("Skewed Job");
}
}
这个代码的解释如下:
先加载数据源,然后在 map 算子里面就是直接把数据返回了,在这里我使用了一个自定义数据源的方法:
package com.atguigu.source;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import java.util.Random;
public class DataGeneratorSource2 implements SourceFunction<Tuple2<Integer, String>> {
private volatile boolean isRunning = true;
private final int maxUserId;
private final Random random = new Random();
public DataGeneratorSource2(int maxUserId) {
this.maxUserId = maxUserId;
}
@Override
public void run(SourceContext<Tuple2<Integer, String>> ctx) throws Exception {
while (isRunning) {
// Generate data for a random user
int userId = random.nextInt(maxUserId) + 1;
String action = random.nextBoolean() ? "click" : "view";
ctx.collect(new Tuple2<>(userId, action));
Thread.sleep(10); // Sleep to simulate time gap between events
}
}
@Override
public void cancel() {
isRunning = false;
}
}
在MyProcessFunction 类里面也就是把数据发往下游,代码如下:
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
public class MyProcessFunction extends KeyedProcessFunction<Integer, Tuple2<Integer, String>, Integer> {
@Override
public void processElement(
Tuple2<Integer, String> value,
KeyedProcessFunction<Integer, Tuple2<Integer, String>, Integer>.Context ctx,
Collector<Integer> out) throws Exception {
// 实现你的逻辑
// 例如, 可以直接收集第一个字段:
out.collect(value.f0);
// 你还可以使用Context参数来注册定时器或访问键控状态等
// ctx.timerService().registerEventTimeTimer(...);
}
}
最后运行的结果如下:

数据倾斜的优化
代码如下:
import com.atguigu.source.DataGeneratorSource2;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
public class RebalancedJob {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 8083);
final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
int parallelism = 10;
Integer[] rebalanceKeys = RebalanceKeyCreator.generateRebalanceKeys(parallelism);
int maxUserId = 100; // 假设我们有100个不同的用户ID
env.setParallelism(10);
// 使用自定义数据源
DataGeneratorSource2 dataSource = new DataGeneratorSource2(maxUserId);
// 将数据源添加到环境中,并定义后续的转换操作
SingleOutputStreamOperator<Tuple2<Integer, String>> skewedInput = env.addSource(dataSource)
.name("Custom Data Source")
.setParallelism(1);// 设置数据源的并行度
skewedInput
.map(new MapFunction<Tuple2<Integer, String>, Tuple2<Integer, String>>() {
@Override
public Tuple2<Integer, String> map(Tuple2<Integer, String> value) throws Exception {
int newKey = rebalanceKeys[value.f0 % parallelism];
return new Tuple2<>(newKey, value.f1);
}
})
.keyBy(event -> event.f0)
.process(new KeyedProcessFunction<Integer, Tuple2<Integer, String>, Tuple2<Integer, String>>() {
@Override
public void processElement(Tuple2<Integer, String> value, Context ctx, Collector<Tuple2<Integer, String>> out) throws Exception {
// 处理每个元素的地方
out.collect(value);
}
});
env.execute("Rebalanced Job");
}
}
代码解释:
这个优化的代码,和上面存在数据倾斜的例子中的代码是几乎一样的。
就是加了我们上篇文章说的优化思路里面的代码,如下:
public class RebalanceKeyCreator {
public static Integer[] generateRebalanceKeys(int parallelism) {
int maxParallel = KeyGroupRangeAssignment.computeDefaultMaxParallelism(parallelism);
int maxKey = parallelism * 12;
Map<Integer, Integer> subIndexKeyMap = new HashMap<>();
for (int key = 0; key < maxKey; key++) {
int subtaskIdx = KeyGroupRangeAssignment.assignKeyToParallelOperator(key, maxParallel, parallelism);
if (!subIndexKeyMap.containsKey(subtaskIdx)) {
subIndexKeyMap.put(subtaskIdx, key);
}
}
return subIndexKeyMap.values().toArray(new Integer[0]);
}
}
然后在 Flink 任务里面进行调用,如下:
Integer[] rebalanceKeys = RebalanceKeyCreator.generateRebalanceKeys(parallelism); int newKey = rebalanceKeys[value.f0 % parallelism];
优化过后的效果如下:
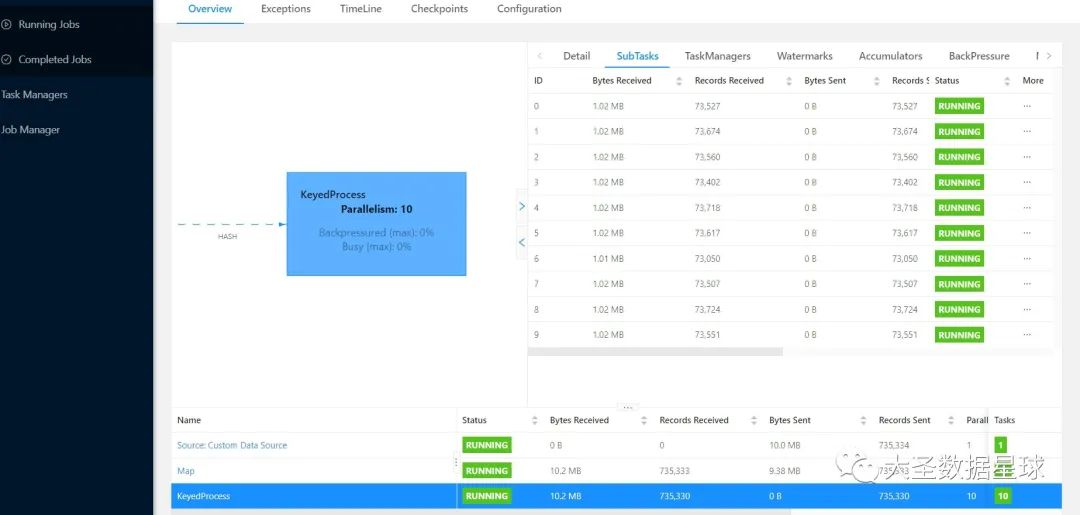
代码讲解
其实在优化的时候,思路就是在Flink任务中先把当前程序的并行度给传入generateRebalanceKeys() 里面,然后使得每一个并行度上面都有对应且唯一的key,然后返回 hashmap。
接着再 map 算子里面 通过 int newKey = rebalanceKeys[value.f0 % parallelism]; 这一行代码得到新的 newkey,后面 keyby 的时候拿这个 newkey 去进行 keyby 就可以了。
value.f0 % parallelism 这个得到的值就是 [0,parallelism - 1] 也就是我们Flink 每个并行度。
最后为什么这样可以解决数据倾斜,代码的设计原理和思想在上一篇文章当中我们详细讲解过,如果有不清楚的可以上篇文章去看看。
使用场景
需要注意的点
注意点1
如果使用了优化的方案,而且在 keyby 算子后使用了 keystate 的话,会出现可能多个原来的key合并到一个 newkey 上面,看下面的例子:
UserID: 1 -> Rebalance Key: 100
UserID: 2 -> Rebalance Key: 100
UserID: 3 -> Rebalance Key: 101
UserID: 4 -> Rebalance Key: 101
在这种情况下,当我们使用Rebalance Key来进行键控操作时,
UserID 1和2的状态将被合并到Rebalance Key 100的状态中,UserID 3和4的状态将被合并到Rebalance Key 101的状态中。
解决方案1:在状态中存储用户信息
你可以使用MapState<原始键, 状态>,这里的“原始键”是用户ID,状态是你需要跟踪的用户特定信息。当处理一个事件时,你将基于映射的新键来访问状态,然后在该状态中使用原始键来更新正确的用户数据。
MapState<Integer, UserBehaviorState> state; // 假设UserBehaviorState是某种包含用户行为信息的数据结构
每次处理事件时:
// 假设value是输入事件,newKey是通过Rebalance Key得到的新键
UserBehaviorState userState = state.get(value.f0); // 使用原始键(用户ID)来获取状态
if (userState == null) {
userState = new UserBehaviorState(); // 如果还没有为这个用户ID创建状态,则创建一个新的
}
// 更新状态
// ...
state.put(value.f0, userState); // 保存更新后的状态
注意点2
当我们进行扩容或者缩容的的时候,我觉得可能也会出现一些问题,我研究了一下午,没想明白。
所以我现在还没想清楚这一块我逻辑,暂时给不了明确的答案。‘
我接下来的时间再把这个逻辑给彻底梳理明白,然后给大家单独写一篇文章来说明。
注意点3
我觉得当有一个 key 的数据非常大的时候,这种方案也是不可取的,因为你无论怎么去映射,这个key 都会落到同一个并行度上面。
所以我觉得这也是这个方案解决不了的。
这种情况一般采取二阶段聚合的思路去解决。
个人理解
我个人觉得上面这种优化的方案适合有多个 key,然后可能有一个并行度上面可能没有映射到 key 的情况,这种数据倾斜就比较适合我们上面的方案。
就如同我上面举得例子一样,你可以很清晰的看到在优化的方案中,十个并行度处理的数据是很均匀的。
但是没有优化的方案中,就出现了倾斜。
彩蛋
给大家分享一个直接在本地IDE 里面跑 Flink 任务,我们也可以打开 Flink UI 界面的小技巧。
添加依赖
除了 Flink 那些核心依赖之外,大家还添加下面这个依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_2.12</artifactId>
<version>1.13.6</version>
<scope>provided</scope>
</dependency>
创建环境
Configuration conf = new Configuration();
conf.setInteger("rest.port", 8082);
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
上面两步做完之后,我们在启动 Flink 任务之后,在浏览器里面输入 localhost:8082 就可以看到 Flink UI 界面了
注意那个 8082 的端口不是唯一的,大家也可以改自己的端口就行。
总结
这篇文章把我们的优化方案给落地了,也让大家看到了优化的效果。
但是其中有一些点我还是没有讲清楚,我后面时间彻底把这个知识点给理解透彻,然后单独给大家写一篇文章来说,希望大家见谅。
大家想要上面代码,在本地测试的。
这篇关于深入Flink : 源码解读数据倾斜代码落地的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-04-07答网友24个有关DBA课程的问题
- 2024-04-07夯实智慧新能源数据底座,TiDB Serverless 在 Sandisolar+ 的应用实践
- 2024-03-2303-Spark SQL入门
- 2024-03-16离线数仓建设之数据导出
- 2024-03-15数仓开发之ODS层
- 2024-03-11tsv文件在大数据技术栈里的应用场景
- 2024-03-10hive分区和分桶你熟悉吗?
- 2024-03-03内含资料下载丨黄东旭:2024 现代应用开发关键趋势——降低成本、简化架构
- 2024-02-23Runaway Queries 管理:提升 TiDB 稳定性的智能引擎
- 2024-02-23数据价值在线化丨TiDB 在企查查数据中台的应用及 v7.1 版本升级体验



