「布道师系列文章」小红书黄章衡:AutoMQ Serverless 基石-秒级分区迁移
2024/5/8 21:02:48

本文主要是介绍「布道师系列文章」小红书黄章衡:AutoMQ Serverless 基石-秒级分区迁移,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
作者|黄章衡,小红书消息引擎研发专家
01 引言
Apache Kafka 因存算一体化架构,分区迁移依赖大量数据同步的完成,以一个 100MB/s 流量的 Kafka 分区为例,运行一天产生的数据量约为 8.2T,如果此时需要将该分区迁移到其他 Broker,则需要对全量数据进行复制,即使对拥有 1 Gbps 带宽的节点,也需要小时级的时间来完成迁移,这使得 Apache Kafka 集群几乎不具备实时弹性能力。
而得益于 AutoMQ Kafka 的存算分离架构,在实际进行分区迁移时无需搬迁任何数据,这使得将分区迁移时间缩短至秒级成为了可能。
本篇文章将详细解析 AutoMQ 秒级迁移能力对应的原理和源码部分,并在最后讨论秒级迁移能力的应用场景。
02 AutoMQ 分区迁移流程概述
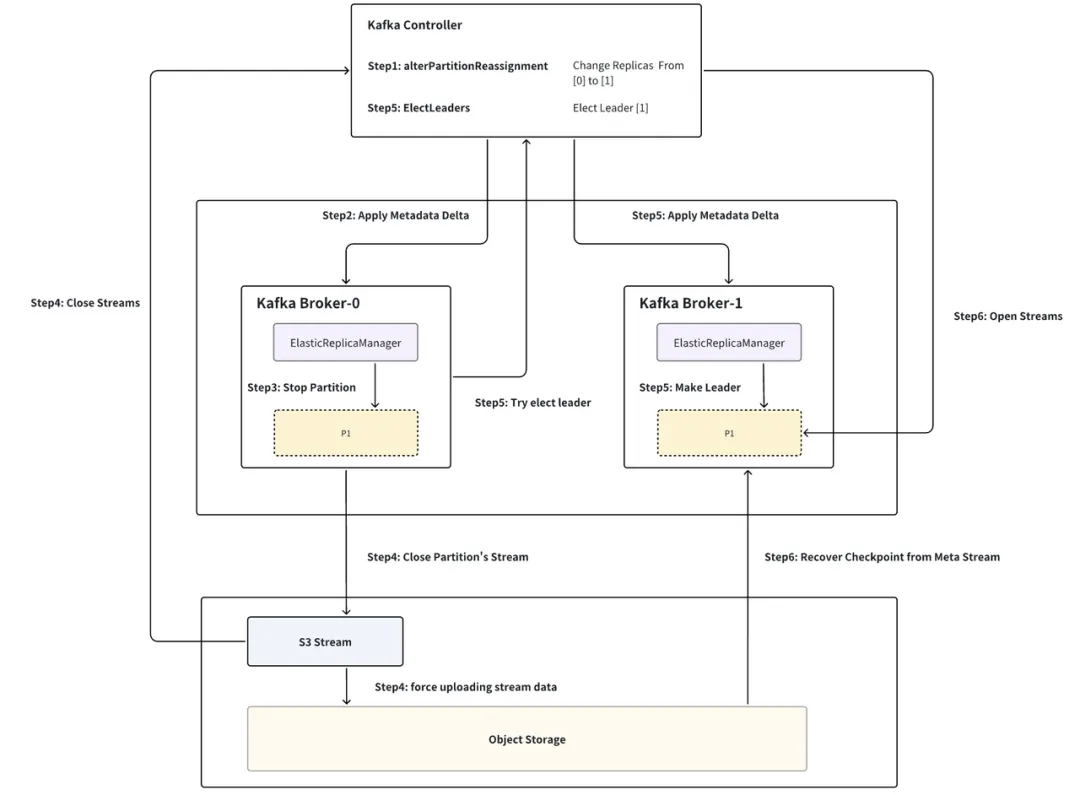
如下图,以分区 P1 从 Broker-0 迁移至 Broker-1 为例,流程分为六步:
ꔷ Step1 构建分区迁移命令: Controller(ReplicationControlManager:AlterPartitionReassign)当 Kraft Controller 收到分区迁移命令时,会构建出相应的 PartitionChangeRecord 并 commit 至 Kraft Log 层,将 Broker-0 从 leader replica 列表中删除,并将 Broker-1 加入 follower replica 列表中。
ꔷ Step2 Broker 同步分区变更: Broker(ElasticReplicaManager:AsyncApplyDelta)Broker-0 同步 Kraft Log 监听到 P1 分区变更,进入分区关闭流程。
ꔷ Step3 元数据持久化与分区 Stream 关闭: Broker (ElasticLog: Close) ElasticLog 为 LocalLog 基于 S3Stream 的实现。ElasticLog 会先持久化分区元数据至 Meta Stream(包括 LeaderEpoch、ProducerSnapshot、SegmentList、StreamIds etc…),随后将 Meta 和 Data Stream 全部 Close。
ꔷ Step4 数据上传与 Stream 关闭: Stream (S3Stream: Close) 每个 Stream 关闭时,若还存在未上传至对象存储的数据,则会触发强制上传,而在一个稳定运行的集群中,这部分数据往往不超过数百 MB,结合目前云厂商提供的突发网络带宽能力,这个过程一般仅需秒级即可完成。当 Stream 的数据上传完成后,即可安全的上报 Controller 关闭该 Stream 并从 Broker-0 删除分区 P1。
ꔷ Step5 主动重新触发选主: Controller (ReplicationControlManager:ElectLeader) P1 从 Broker 完成关闭后会主动触发一次选主,此时 Broker-1 作为唯一的 replica 晋升为 P1 的 leader,进入分区恢复流程。
ꔷ Step6 分区恢复与数据恢复: Broker (ElasticLog: Apply) 分区恢复时,会先上报 Controller 打开 P1 对应的 Meta Stream,根据 Meta Stream 从对象存储中拉取 P1 对应的元数据,从而恢复出 P1 相应的 checkpoint(Leader Epoch/SegmentList etc…),后根据 P1 的关闭状态(是否为 cleaned shutdown)进行对应的数据恢复。
03 AutoMQ 分区迁移流程源码解析
接下来我们详细解析分区迁移六步骤的源码,仍然以分区 P1 从 Broker-0 迁移至 Broker-1 为例:
注:AutoMQ 关闭分区前,需要先上报 Controller 关闭分区对应的所有 Stream 使其变为 Closed State,以便分区恢复时能够重新打开 Stream 使其变为 Opened State。这么做的目的是防止脑裂(也即两台 Broker 同时打开同一个 Stream),统一由 Controller 调控 Stream 的 State 和 Owner。
Step1: Controller 构建分区迁移命令
当 Controller 收到 alterPartitionReassignments 指令时,会构建 PartitionChangeBuilder 将该 Partition 的 TargetISR、Replicas 设置为目标 [1],但不会直接选举 Leader 而是选择延后选举,以保障选举前分区对应的 Stream 已经正常关闭。
此外,流程中还设置了分区选主超时器,若一段时间内源Broker 没有成功触发选主,则会在 Controller 中主动触发选主。
ReplicationControlManager:changePartitionReassignmentV2 {
PartitionChangeBuilder builder = new PartitionChangeBuilder(part,
tp.topicId(),
tp.partitionId(),
// no leader election, isAcceptableLeader 直接返回 False,代表不选主
brokerId -> false,
featureControl.metadataVersion(),
getTopicEffectiveMinIsr(topics.get(tp.topicId()).name.toString())
);
builder.setZkMigrationEnabled(clusterControl.zkRegistrationAllowed());
builder.setEligibleLeaderReplicasEnabled(isElrEnabled());
// 设置 ISR、Replicas 为 [target.replicas().get(0)]
builder.setTargetNode(target.replicas().get(0));
TopicControlInfo topicControlInfo = topics.get(tp.topicId());
if (topicControlInfo == null) {
log.warn("unknown topicId[{}]", tp.topicId());
} else {
// 选主超时器
TopicPartition topicPartition = new TopicPartition(topicControlInfo.name, tp.partitionId());
addPartitionToReElectTimeouts(topicPartition);
}
return builder.setDefaultDirProvider(clusterDescriber).build();
}
Step2: Broker 同步分区变更
Controller 更新 Partition 的 Replicas 后,Broker-0 同步 Kraft Log 监听到 P1 分区变更,该分区不再属于 Broker-0,因此进入分区关闭流程。
ElasticReplicaManager: asyncApplyDelta(delta: TopicsDelta, newImage: MetadataImage) {
if (!localChanges.deletes.isEmpty) {
val deletes = localChanges.deletes.asScala
.map { tp =>
val isCurrentLeader = Option(delta.image().getTopic(tp.topic()))
.map(image => image.partitions().get(tp.partition()))
.exists(partition => partition.leader == config.nodeId)
val deleteRemoteLog = delta.topicWasDeleted(tp.topic()) && isCurrentLeader
StopPartition(tp, deleteLocalLog = true, deleteRemoteLog = deleteRemoteLog)
}
.toSet
def doPartitionDeletion(): Unit = {
stateChangeLogger.info(s"Deleting ${deletes.size} partition(s).")
deletes.foreach(stopPartition => {
val opCf = doPartitionDeletionAsyncLocked(stopPartition)
opCfList.add(opCf)
})
}
doPartitionDeletion()
}
}
Step3: Broker 元数据持久化与分区 Stream 关闭
当 ReplicasManager 调用 StopPartition 后,会一层层调用至 ElasticLog.Close.ElasticLog 为 LocalLog 基于 S3Stream 的实现,分区的数据和元数据与 S3Stream 的对应关系如下:
-
每个 Segment 被映射到 DataStream
-
Segment 的 TxnIndex 和 TimeIndex 为别被映射为 Txn Stream 和 Time Stream
-
分区的元数据 (producerSnapshot、LeaderEpoch、Streamids、SegmentList …)则以KV的形式映射为 Meta Stream
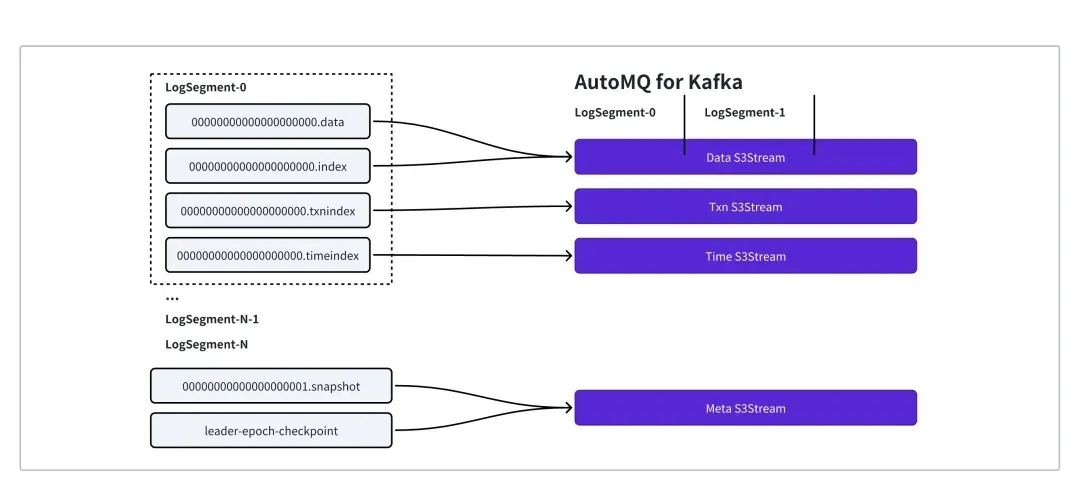
ElasticLog 会先持久化分区元数据至 Meta Stream,随后将 Meta 和 Data Stream 全部 Close:
ElasticLog close(): CompletableFuture[Void] = {
// already flush in UnifiedLog#close, so it's safe to set cleaned shutdown.
// 标志为 Clean Shutdown
partitionMeta.setCleanedShutdown(true)
partitionMeta.setStartOffset(logStartOffset)
partitionMeta.setRecoverOffset(recoveryPoint)
maybeHandleIOException(s"Error while closing $topicPartition in dir ${dir.getParent}") {
// 持久化元数据
CoreUtils.swallow(persistLogMeta(), this)
CoreUtils.swallow(checkIfMemoryMappedBufferClosed(), this)
CoreUtils.swallow(segments.close(), this)
CoreUtils.swallow(persistPartitionMeta(), this)
}
info("log(except for streams) closed")
// 关闭分区对应的所有 Streams
closeStreams()
}
Step4: S3Strema 数据上传与关闭
每个 Stream 关闭时:
- 等待所有未完成的 request
- 若还存在未上传至对象存储的数据,则会触发强制上传,而在一个稳定运行的集群中,这部分数据往往不超过数百 MB,结合目前云厂商提供的突发网络带宽能力,这个过程一般仅需秒级即可完成
- 当 Stream 的数据上传完成后,即可安全的上报 Controller 关闭该 Stream
S3Stream:Close(){
// await all pending append/fetch/trim request
List<CompletableFuture<?>> pendingRequests = new ArrayList<>(pendingAppends);
if (GlobalSwitch.STRICT) {
pendingRequests.addAll(pendingFetches);
}
pendingRequests.add(lastPendingTrim);
CompletableFuture<Void> awaitPendingRequestsCf = CompletableFuture.allOf(pendingRequests.toArray(new CompletableFuture[0]));
CompletableFuture<Void> closeCf = new CompletableFuture<>();
// Close0 函数触发强制上传和 Stream 关闭
awaitPendingRequestsCf.whenComplete((nil, ex) -> propagate(exec(this::close0, LOGGER, "close"), closeCf));
}
private CompletableFuture<Void> close0() {
return storage.forceUpload(streamId)
.thenCompose(nil -> streamManager.closeStream(streamId, epoch));
}
Step5: Broker 主动重新触发选主
P1 从 Broker 完成关闭后会主动触发一次选主:
ElasticReplicaManager:StopPartitions(partitionsToStop: collection.Set[StopPartition]) {
partitionsToStop.foreach { stopPartition =>
val topicPartition = stopPartition.topicPartition
if (stopPartition.deleteLocalLog) {
getPartition(topicPartition) match {
case hostedPartition: HostedPartition.Online =>
if (allPartitions.remove(topicPartition, hostedPartition)) {
maybeRemoveTopicMetrics(topicPartition.topic)
// AutoMQ for Kafka inject start
if (ElasticLogManager.enabled()) {
// For elastic stream, partition leader alter is triggered by setting isr/replicas.
// When broker is not response for the partition, we need to close the partition
// instead of delete the partition.
val start = System.currentTimeMillis()
hostedPartition.partition.close().get()
info(s"partition $topicPartition is closed, cost ${System.currentTimeMillis() - start} ms, trigger leader election")
// 主动触发选主
alterPartitionManager.tryElectLeader(topicPartition)
} else {
// Logs are not deleted here. They are deleted in a single batch later on.
// This is done to avoid having to checkpoint for every deletions.
hostedPartition.partition.delete()
}
// AutoMQ for Kafka inject end
}
case _ =>
}
partitionsToDelete += topicPartition
}
}
Controller 中, Broker-1 作为唯一的 replica 晋升为 P1 的 leader,进入分区恢复流程
Step6: Broker 分区恢复与数据恢复
Broker 分区恢复时,会先上报 Controller 打开 P1 对应的 Meta Stream,根据 Meta Stream 从对象存储中拉取 P1 对应的元数据,从而恢复出 P1 相应的 checkpoint(Leader Epoch/SegmentList etc…),后根据 P1 的关闭状态(是否为 cleaned shutdown)进行对应的数据恢复。
代码部分对应 ElasticLog:Apply
ꔷ 步骤一:Open Meta Stream
metaStream = if (metaNotExists) {
val stream = createMetaStream(client, key, replicationFactor, leaderEpoch, logIdent = logIdent)
info(s"${logIdent}created a new meta stream: stream_id=${stream.streamId()}")
stream
} else {
val metaStreamId = Unpooled.wrappedBuffer(value.get()).readLong()
// open partition meta stream
val stream = client.streamClient().openStream(metaStreamId, OpenStreamOptions.builder().epoch(leaderEpoch).build())
.thenApply(stream => new MetaStream(stream, META_SCHEDULE_EXECUTOR, logIdent))
.get()
info(s"${logIdent}opened existing meta stream: stream_id=$metaStreamId")
stream
}
ꔷ 步骤二:从 MetaStream 拉取 Partition MetaInfo、Producer Snapshot 等分区元信息
// load meta info for this partition
val partitionMetaOpt = metaMap.get(MetaStream.PARTITION_META_KEY).map(m => m.asInstanceOf[ElasticPartitionMeta])
if (partitionMetaOpt.isEmpty) {
partitionMeta = new ElasticPartitionMeta(0, 0, 0)
persistMeta(metaStream, MetaKeyValue.of(MetaStream.PARTITION_META_KEY, ElasticPartitionMeta.encode(partitionMeta)))
} else {
partitionMeta = partitionMetaOpt.get
}
info(s"${logIdent}loaded partition meta: $partitionMeta")
//load producer snapshots for this partition
val producerSnapshotsMeta = metaMap.get(MetaStream.PRODUCER_SNAPSHOTS_META_KEY).map(m => m.asInstanceOf[ElasticPartitionProducerSnapshotsMeta]).getOrElse(new ElasticPartitionProducerSnapshotsMeta())
val snapshotsMap = new ConcurrentSkipListMap[java.lang.Long, ByteBuffer](producerSnapshotsMeta.getSnapshots)
if (!snapshotsMap.isEmpty) {
info(s"${logIdent}loaded ${snapshotsMap.size} producer snapshots, offsets(filenames) are ${snapshotsMap.keySet()} ")
} else {
info(s"${logIdent}loaded no producer snapshots")
}
// load leader epoch checkpoint
val leaderEpochCheckpointMetaOpt = metaMap.get(MetaStream.LEADER_EPOCH_CHECKPOINT_KEY).map(m => m.asInstanceOf[ElasticLeaderEpochCheckpointMeta])
val leaderEpochCheckpointMeta = if (leaderEpochCheckpointMetaOpt.isEmpty) {
val newMeta = new ElasticLeaderEpochCheckpointMeta(LeaderEpochCheckpointFile.CURRENT_VERSION, List.empty[EpochEntry].asJava)
// save right now.
persistMeta(metaStream, MetaKeyValue.of(MetaStream.LEADER_EPOCH_CHECKPOINT_KEY, ByteBuffer.wrap(newMeta.encode())))
newMeta
} else {
leaderEpochCheckpointMetaOpt.get
}
info(s"${logIdent}loaded leader epoch checkpoint with ${leaderEpochCheckpointMeta.entries.size} entries")
if (!leaderEpochCheckpointMeta.entries.isEmpty) {
val lastEntry = leaderEpochCheckpointMeta.entries.get(leaderEpochCheckpointMeta.entries.size - 1)
info(s"${logIdent}last leaderEpoch entry is: $lastEntry")
}
ꔷ 步骤三:从 MetaStream 拉取 SegmentList 并恢复所有 Segment 状态:
val logMeta: ElasticLogMeta = metaMap.get(MetaStream.LOG_META_KEY).map(m => m.asInstanceOf[ElasticLogMeta]).getOrElse(new ElasticLogMeta())
logStreamManager = new ElasticLogStreamManager(logMeta.getStreamMap, client.streamClient(), replicationFactor, leaderEpoch)
val streamSliceManager = new ElasticStreamSliceManager(logStreamManager)
val logSegmentManager = new ElasticLogSegmentManager(metaStream, logStreamManager, logIdent)
// load LogSegments and recover log
val segments = new CachedLogSegments(topicPartition)
// 这里通过 ElasticLogLoader 恢复所有 elastic log segment 的状态
val offsets = new ElasticLogLoader(
logMeta,
segments,
logSegmentManager,
streamSliceManager,
dir,
topicPartition,
config,
time,
hadCleanShutdown = partitionMeta.getCleanedShutdown,
logStartOffsetCheckpoint = partitionMeta.getStartOffset,
partitionMeta.getRecoverOffset,
Optional.empty(),
producerStateManager = producerStateManager,
numRemainingSegments = numRemainingSegments,
createAndSaveSegmentFunc = createAndSaveSegment(logSegmentManager, logIdent = logIdent)).load()
info(s"${logIdent}loaded log meta: $logMeta")
04 秒级分区迁移
1)高峰期快速扩容
Kafka 运维人员通常会根据历史经验准备 Kafka 集群容量,然而总会有一些非预期中的热门事件和活动导致集群流量陡增。这时候就需要快速的将集群扩容并重平衡分区,来应对突发流量。
在 Apache Kafka 中,由于存储和计算紧密耦合,集群扩容往往需要搬迁 Partition 数据,这个过程需要耗费大量的时间和资源,在高峰期则无法高效的完成扩容。
而在 AutoMQ 中,由于存储和计算分离,扩容过程则无需涉及数据的搬迁。这意味着在高峰期需要快速扩容时,AutoMQ 能够更加灵活地响应,减少了扩容过程的时间和对业务的影响。
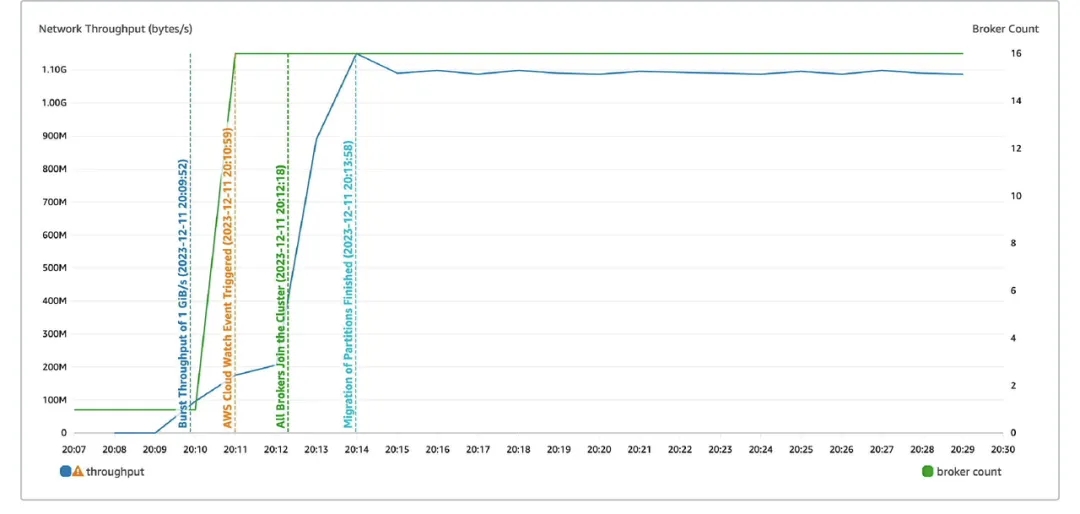
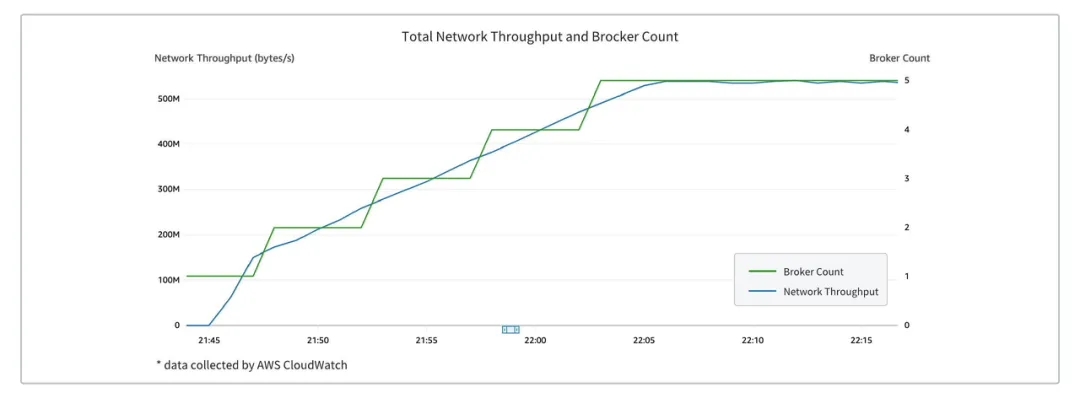
AutoMQ 具备极强的弹性能力,能够在5分钟内完成支撑1GB流量的扩容流程:
2) Serverless 按需扩容
AutoMQ 架构的另一个优势在于其能够实现 Serverless 按需扩容。
在传统的架构中,扩容往往需要手动调整服务器的规模,或者预先分配一定的资源。然而,AutoMQ 的存算分离架构使得扩容过程变得更加灵活和自动化。由于存储和计算分离,可以结合容器 HPA、云厂商的弹性部署组,根据实际流量需求自动地调整计算资源,而无需考虑存储数据的搬迁问题。这使得系统能够更好地应对流量的波动,同时也降低了运维的复杂性和机器成本。
布道师计划
加入 AutoMQ 布道师,共创开源生态!
详情点击:2024 AutoMQ 布道师计划
*AutoMQ 在法律允许范围内,保留对本次活动的最终解释权
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com
👀 B站:AutoMQ官方账号
🔍 视频号:AutoMQ
这篇关于「布道师系列文章」小红书黄章衡:AutoMQ Serverless 基石-秒级分区迁移的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-05-08「布道师系列文章」解析 AutoMQ 对象存储中的文件存储格式
- 2024-05-08AutoMQ 系统测试体系揭秘
- 2024-03-14AutoMQ 携手阿里云共同发布新一代云原生 Kafka,帮助得物有效压缩 85% Kafka 云支出!
- 2024-02-22kafka partitioner
- 2024-01-24AutoMQ生态集成 - 将数据从 AutoMQ Kafka 导入 RisingWave 数据库
- 2024-01-13消息队列面试题:为什么要使用消息队列?
- 2024-01-08"基于 XHAMQ 的消息队列系统实现"
- 2023-11-24全网最全图解Kafka适用场景
- 2023-09-19RabbitMQ 消息应答
- 2023-09-18Flink Sink Kafka 和 Flink 端到端一致性建议



