『互联网架构』kafka集群搭建和使用
2022/8/16 4:22:49

本文主要是介绍『互联网架构』kafka集群搭建和使用,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
之前主要是理论说了kafka的原理,kafka相关的三个比较重要的配置文件server,consumer,Producer的详细配置,以及kafka消息的存储形式,主要是保存在zookeeper上。应该按照之前的文档单实例的kafka都搭建成功了。这次主要说说集群的搭建。

(一)kafka集群的搭建
- 查看主题
cd /opt/kafka_2.12-2.2.1 bin/kafka-topics.sh --list --zookeeper localhost:2181 #__consumer_offsets 记录偏移量的 # test 主题的名称

- 搭建集群
单个节点挂了就挂了,为了让项目高可用必须搭建多节点。在生产环境肯定不能使用单节点肯定是使用多节点。到目前为止,我们都是在一个单节点上运行broker,这并没有什么意思。对于kafka来说,一个单独的broker意味着kafka集群中只有一个接点。要想增加kafka集群中的节点数量,只需要多启动几个broker实例即可。为了有更好的理解,现在我们在一台机器上同时启动三个broker实例,搭建伪分布。其实搭建多台也是一样的。
首先,我们需要建立好其他2个broker的配置文件
cd /opt/kafka_2.12-2.2.1 cp config/server.properties config/server-1.properties cp config/server.properties config/server-2.properties 配置文件的内容分别如下:
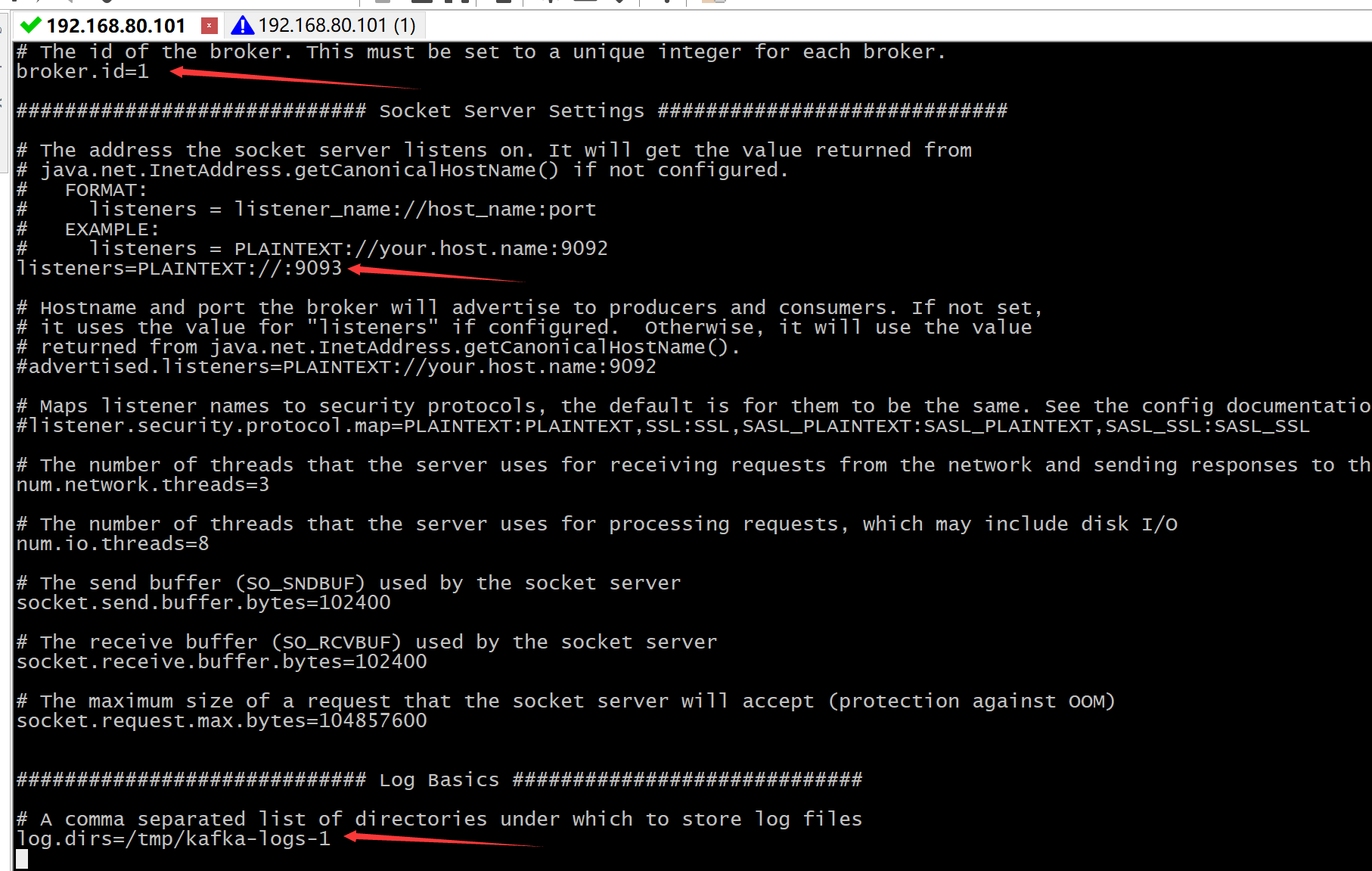
config/server-1.properties
vi config/server-1.properties broker.id=1 #注释放开 listeners=PLAINTEXT://:9093 log.dir=/tmp/kafka-logs-1
config/server-2.properties:
vi config/server-2.properties broker.id=2 #注释放开 listeners=PLAINTEXT://:9094 log.dir=/tmp/kafka-logs-2
broker.id属性在kafka集群中必须要是唯一的。我们需要重新指定port和log目录,因为我们是在同一台机器上运行多个实例。如果不进行修改的话,

目前我们已经有一个zookeeper实例和一个broker实例在运行了,现在我们只需要在启动2个broker实例。
cd /opt/kafka_2.12-2.2.1 bin/kafka-server-start.sh config/server-1.properties &


cd /opt/kafka_2.12-2.2.1 bin/kafka-server-start.sh config/server-2.properties &


- 创建单分区主题:备份因子设置为3,因为有3个节点的集群,不允许设置大概3的。
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
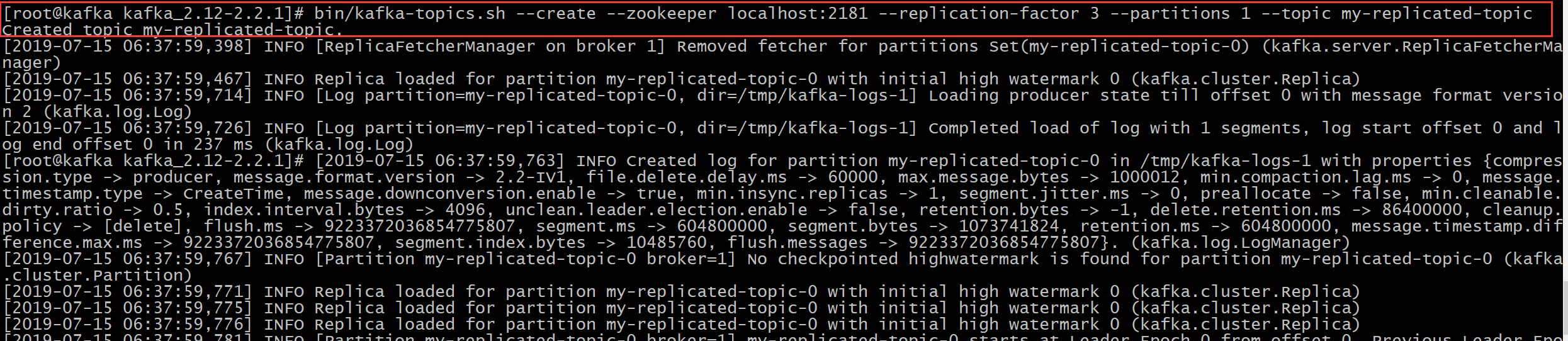
查看集群的主题
bin/kafka-topics.sh --list --zookeeper localhost:2181

现在已经有了集群,并且创建了一个3个备份因子的topic,但是到底是哪一个broker在为这个topic提供服务呢(因为我们只有一个分区,所以肯定同时只有一个broker在处理这个topic)?
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic: 主题的名称
PartitionCount: 因为创建的时候就创建了一个分区,目前显示1
ReplicationFactor: 备份因子是3个
Partition:分区在这个主题的编号
Leader:编号为1的broker.id,这个主题对外提供读写的节点的是编号为1的节点。
Replicas:副本编号1,2,0
Isr:已经同步的副本1,2,0

- 删除一个Leader节点查看描述
#通过配置文件找到对应的进程id ps -ef | grep server-1.pro
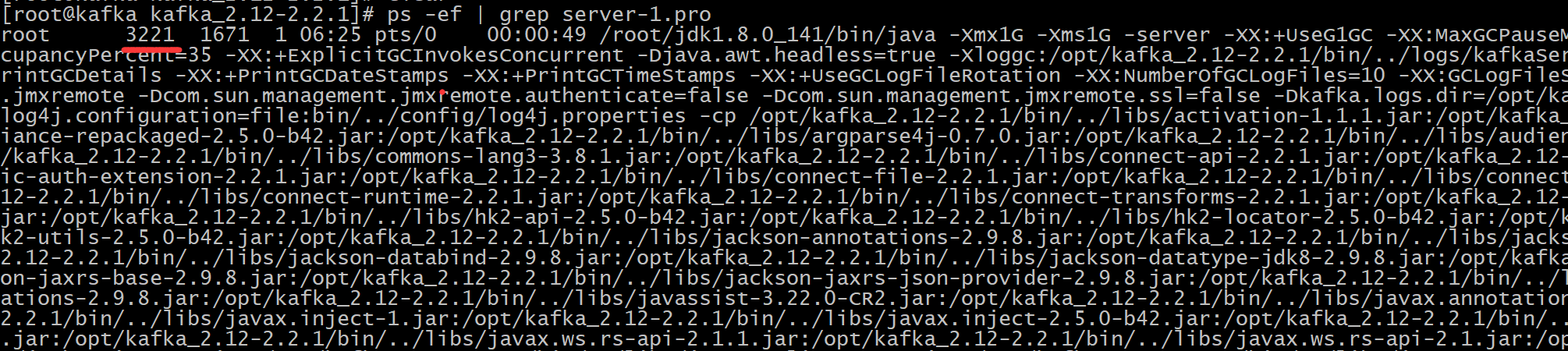
kill -9 3221 #剩余2个kafka jps


#删除了broker.id=1 bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
删除了broker.id=1的节点,剩余2个节点0和2,进行选举leader。目前的leader变成了2,副本还是3个,活着已同步的节点没有1了。

- 创建多分区主题:备份因子设置为2,重新启动broker.id=1,有3个节点的集群,分区设置2。
jps bin/kafka-server-start.sh config/server-1.properties & jps # 创建新主题 bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 2 --topic my-test2 # 查看主题列表 bin/kafka-topics.sh --list --zookeeper localhost:2181

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fmyrE1Rf-1660548389743)(https://upload-images.jianshu.io/upload_images/11223715-242f9181189bd0e3.png?imageMogr2/auto-orient/strip|imageView2/2/w/1240)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U3Ay9BDU-1660548389745)(https://upload-images.jianshu.io/upload_images/11223715-1cc38e8083c8f0b7.png?imageMogr2/auto-orient/strip|imageView2/2/w/1240)]
查看主题的情况my-test2,2个分区,2个备份因子。2个分区每个分区有个leader。一定要明白leader是分区的leader,不是节点的leader。
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-test2

- 单播消费
一条消息只能被某一个消费者消费的模式,类似queue模式,只需让所有消费者在同一个消费组里即可
分别在两个客户端执行如下消费命令,然后往主题里发送消息,结果只有一个客户端能收到消息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGroup --topic test
- 多播消费
一条消息能被多个消费者消费的模式,类似publish-subscribe模式费,针对Kafka同一条消息只能被同一个消费组下的某一个消费者消费的特性,要实现多播只要保证这些消费者属于不同的消费组即可。我们再增加一个消费者,该消费者属于testGroup-2消费组,结果两个客户端都能收到消息。如果2个消费者都属于一个消费组,只能有一个收到。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGroup-2 --topic test
(二)kafka-java客户端调用
- 官方文档
http://kafka.apache.org/documentation/#api
- host文件中加入kafka的host
- 消费者类
package com.idig8.kafka.kafkaDemo;
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
public class MsgConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.80.101:9092");
// 消费分组名
props.put("group.id", "testGroup");
// 是否自动提交offset
//props.put("enable.auto.commit", "true");
// 自动提交offset的间隔时间
//props.put("auto.commit.interval.ms", "1000");
props.put("enable.auto.commit", "false");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
// 消费主题
consumer.subscribe(Arrays.asList("test"));
// 消费指定分区
//consumer.assign(Arrays.asList(new TopicPartition("test", 0)));
while (true) {
/*
* poll() API 主要是判断consumer是否还活着,只要我们持续调用poll(),消费者就会存活在自己所在的group中,
* 并且持续的消费指定partition的消息。底层是这么做的:消费者向server持续发送心跳,如果一个时间段(session.
* timeout.ms)consumer挂掉或是不能发送心跳,这个消费者会被认为是挂掉了,
* 这个Partition也会被重新分配给其他consumer
*/
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
if (records.count() > 0) {
// 提交offset
consumer.commitSync();
}
}
}
}
- 生产者,分为同步和异步两种方式
package com.idig8.kafka.kafkaDemo;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
public class MsgProducer {
public static void main(String[] args) throws InterruptedException, ExecutionException {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.80.101:9092,192.168.80.101:9093");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
for (int i = 0; i < 5; i++) {
//同步方式发送消息
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("test", 0, Integer.toString(i), Integer.toString(i));
/*Future<RecordMetadata> result = producer.send(producerRecord);
//等待消息发送成功的同步阻塞方法
RecordMetadata metadata = result.get();
System.out.println("同步方式发送消息结果:" + "topic-" + metadata.topic() + "|partition-"
+ metadata.partition() + "|offset-" + metadata.offset());*/
//异步方式发送消息
producer.send(producerRecord, new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
System.err.println("发送消息失败:" + exception.getStackTrace());
}
if (metadata != null) {
System.out.println("异步方式发送消息结果:" + "topic-" + metadata.topic() + "|partition-"
+ metadata.partition() + "|offset-" + metadata.offset());
}
}
});
}
producer.close();
}
}
- pom文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.tuling.kafka</groupId> <artifactId>kafkaDemo</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>kafkaDemo</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.3.0</version> </dependency> <!-- 由于新版的客户端没有引入日志框架实现的依赖,所以我们要自己引入 --> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-core</artifactId> <version>1.1.3</version> </dependency> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.1.1</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> </dependencies> </project>
(三)kafka的选举一个图足够了
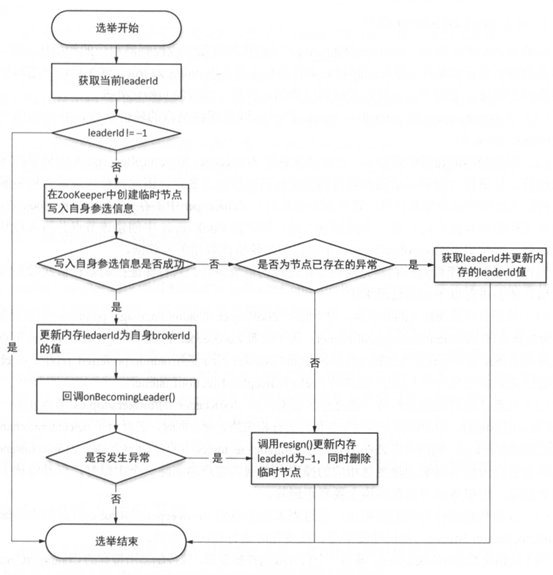
PS:kafka消息不会丢失,只会定期删除。java源码不太负责,直接看官网的api就可以了。消费的方式是通过偏移量来进行的。
这篇关于『互联网架构』kafka集群搭建和使用的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-05-08「布道师系列文章」解析 AutoMQ 对象存储中的文件存储格式
- 2024-05-08「布道师系列文章」小红书黄章衡:AutoMQ Serverless 基石-秒级分区迁移
- 2024-05-08AutoMQ 系统测试体系揭秘
- 2024-03-14AutoMQ 携手阿里云共同发布新一代云原生 Kafka,帮助得物有效压缩 85% Kafka 云支出!
- 2024-02-22kafka partitioner
- 2024-01-24AutoMQ生态集成 - 将数据从 AutoMQ Kafka 导入 RisingWave 数据库
- 2024-01-13消息队列面试题:为什么要使用消息队列?
- 2024-01-08"基于 XHAMQ 的消息队列系统实现"
- 2023-11-24全网最全图解Kafka适用场景
- 2023-09-19RabbitMQ 消息应答



